Image Based English and Persian Text Recognition using RCNN
Introduction
This project is a practical implementation of an article called An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. The proposed algorithm is first tested on English string database and later to prove its generality, the authors train the model on musical notes. This gave me an idea to first, replicate the results on English text and later test it on persian text since it’s my mother tongue.
Researchers often use a combination of Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN). Convolutional neural networks, in the past, have performed very well in detection tasks within the realm of machine vision. Likewise, recurrent neural networks have also performed very well in sequence recognition tasks. So it can be assumed that a mixture of these two should work better in recognizing a sequence of characters in a row (RNN’s task) from an image (CNN’s task).
The model proposed by the mentioned article is comprised of four sets of layers: The first is the input layer, which is simply a 32-pixel-high grayscale image of text. Next are the CNN layers, inspired by the famous VGG model. Following that, there are two bi-directional LSTM layers for the recurrent layer set. Lastly, there is the transcription layer, tasked with transforming the predictions made by the LSTM layers into a sequence of letters.
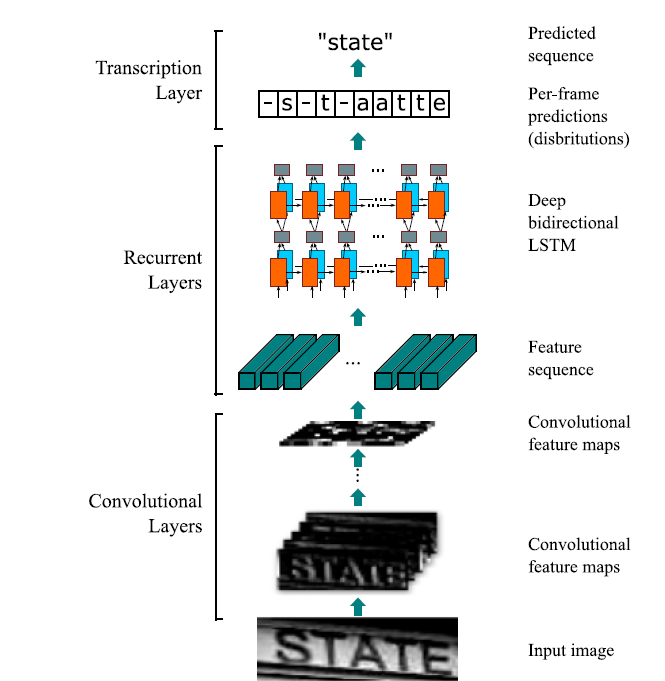
Databases
English
One of the largest databases used in the original article is called MJSynth. This database is comprised of 9 million synthetically generated images using multiple fonts, with various random distortion techniques applied to make the images more realistic.
Since my resources (my laptop’s GPU) were limited, I had to limit myself to using only about 20% of the data (~2 million).

Persian
There were no public databases for images of Persian text. So I took matters into my own hands. I downloaded two dictionaries of Persian words, with a total of 700k words, and synthetically generated my own image database using the same approach as MJSynth. I used 35 different fonts, randomly selected the background and foreground colors, added rotation, distortion, and Gaussian noise.
The results are shown in the image below. As you can see, the variety and randomness are not as great as MJSynth. This was a shortcoming on my part, and it will become important later!

Results
English
After 8 epochs, the sequence accuracy of the train, validation, and test datasets was 91%, 86%, and 86%, respectively. Compared to the original article’s result of 92.3% for the test dataset, my implementation performed worse by 6%. This could be explained by my using only 2 million images for training the model as opposed to the entire 9 million, and also training for a shorter time than the original article.
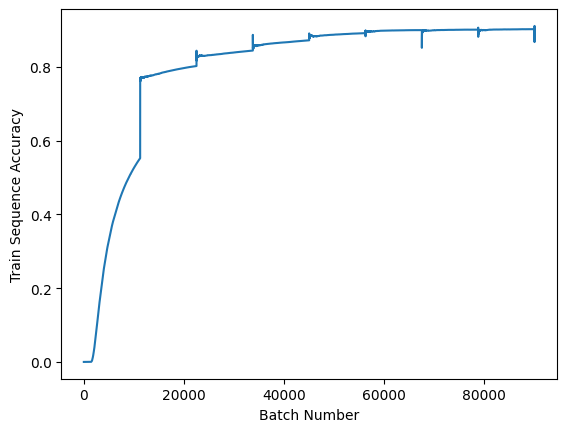
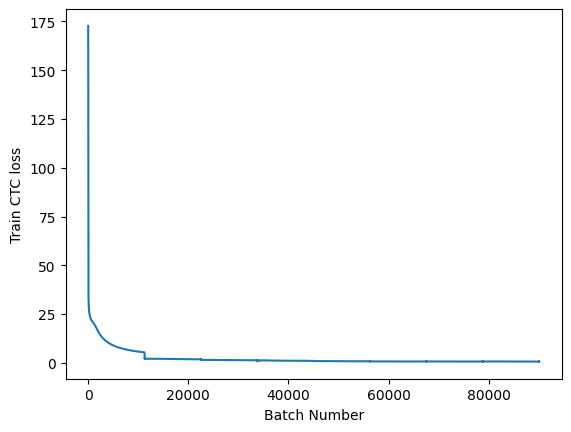
Persian
After 10 epochs, the sequence accuracy of the train, validation, and test datasets was 99.72%, 96.64%, and 96.61%, respectively.
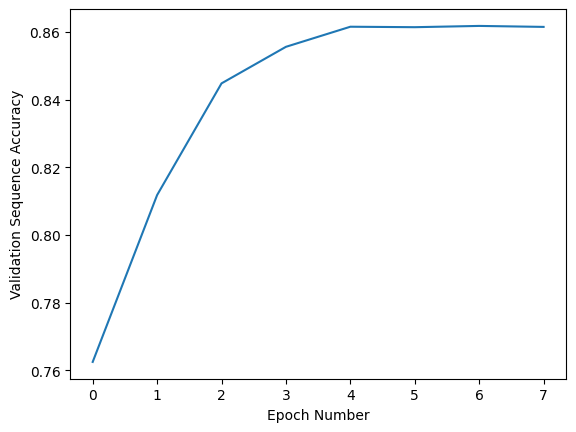
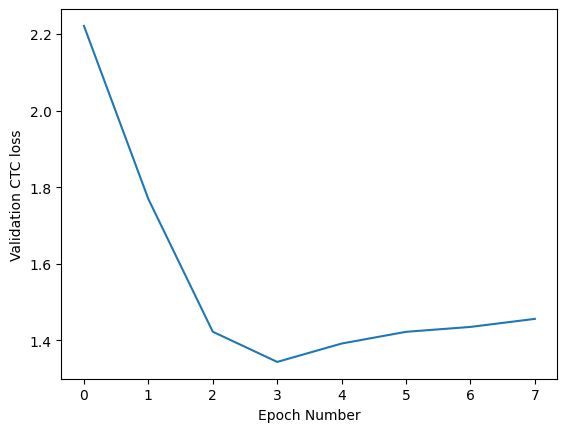
How could the English model, with 3 times the data of the Persian model, perform so much worse? Even though Persian letters are arguably more complex than Latin ones and have more variation depending on how they connect to neighboring letters.
The answer lies in the quality of the database. As mentioned before, the variety in colors, fonts, and randomness of MJSynth is greater and more closely resembles what you might find in the real world. Therefore, it requires more training data to achieve high accuracy. My Persian database, on the other hand, lacks this diversity, so it was easier for the model to pick up patterns and achieve very high accuracy.